RESEARCH↑ trendingReddit r/LocalLLaMA·4/16/2026
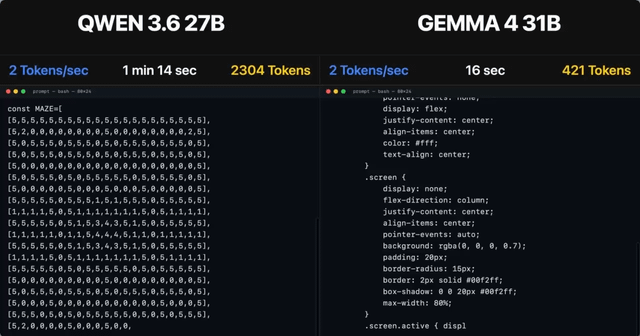
Qwen 3.6 35B A3B, RTX 5090 32GB, 187t/s, Q5 K S, 120K Context Size, Thinking Mode Off, Temp 0.1
Das Qwen 3.6 35B A3B Modell erreicht 187 Tokens pro Sekunde auf einer RTX 5090 32GB GPU. Es unterstützt eine Kontextgröße von 120K, nutzt Q5 K S Quantisierung und eine Temperatur von 0,1.
42