ARTICLE↑ trendingReddit r/LocalLLaMA·4/23/2026
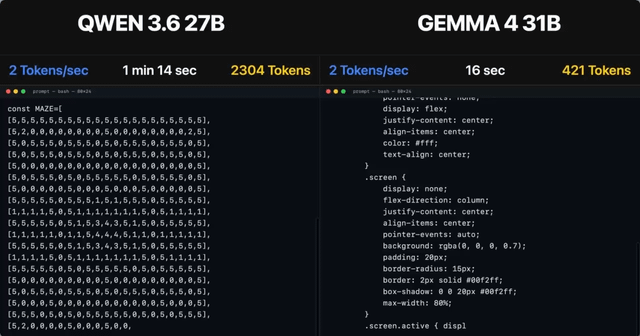
Qwen3.6 can code
Ein Benutzer, frustriert von OpenAI-Modellen, testete Qwen3.6-27b für die Svelte 5-Codegenerierung und erzielte ein perfektes Ergebnis, obwohl es länger dauerte. Er erwartet interessante Entwicklungen in den nächsten 12 Monaten, trotz des informellen Charakters der Bewertung.
52
![Qwen3 4B outperforms cloud agents on code tasks—with Mahoraga research [R]](/cdn-cgi/image/width=3840,quality=75,format=webp/https://external-preview.redd.it/vJR39F6E0ARypSJNijuQ-yR1Ycl5eGsa5LcRuS3CoSM.png?width=140&height=70&auto=webp&s=6b39ed3b63f9683d366c205696aa8805c9cf6143)