ARTICLE↑ trendingHacker News (AI)·vor 2T
Agentic AI solved coding and exposed every other problem in SE
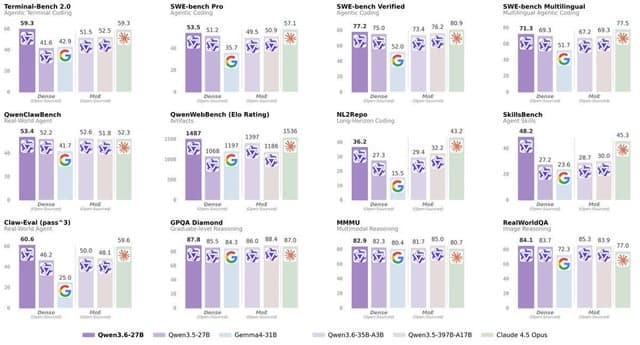
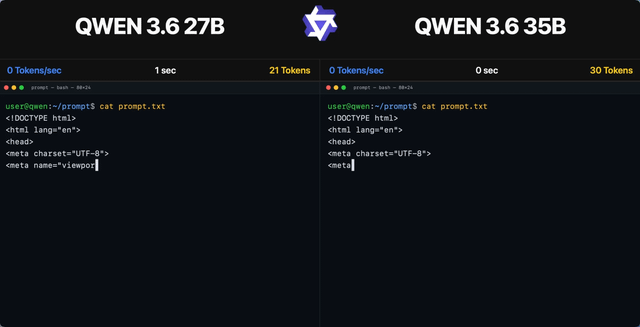
Der Artikel untersucht, wie Agentic AI viele Codierungsherausforderungen gelöst und die Softwareentwicklung verändert hat. Diese Entwicklung deckt jedoch andere hartnäckige Komplexitäten und Probleme im Software-Engineering auf.
72