NEWS↑ trendingReddit r/LocalLLaMA·4/12/2026
GLM 5.1 sits alongside frontier models in my social reasoning benchmark
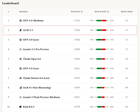
GLM 5.1 erweist sich in sozialem Denken als äußerst konkurrenzfähig gegenüber Spitzenmodellen, basierend auf einem benutzerdefinierten Benchmark mit autonomen Blood on the Clocktower-Spielen. Es bietet eine erhebliche Kosteneffizienz von 0,92 $ pro Spiel im Vergleich zu Claude Opus 4.6s 3,69 $, bei einer Werkzeugfehlerquote von 0 %.
43