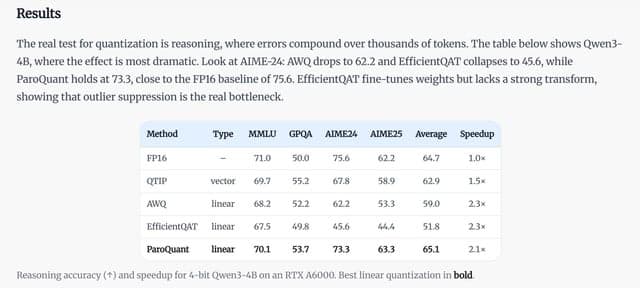
RESEARCHarXiv CS.AI·vor 1T
Accelerated Fourier SAT (AFSAT): Fully Realising a GPU-based Symmetric Pseudo-Boolean SAT Solver
Accelerated Fourier SAT (AFSAT) ist ein GPU-beschleunigter Solver für die pseudo-boolesche Erfüllbarkeit, der auf kontinuierlicher lokaler Suche basiert. Er verbessert die numerische Stabilität, Laufzeitleistung und Speichereffizienz im Vergleich zum Proof-of-Concept erheblich, indem er JAX für parallele Verarbeitung nutzt und Speicher-/Gleitkomma-Einschränkungen behebt.
60