RESEARCH↑ trendingReddit r/LocalLLaMA·4/16/2026
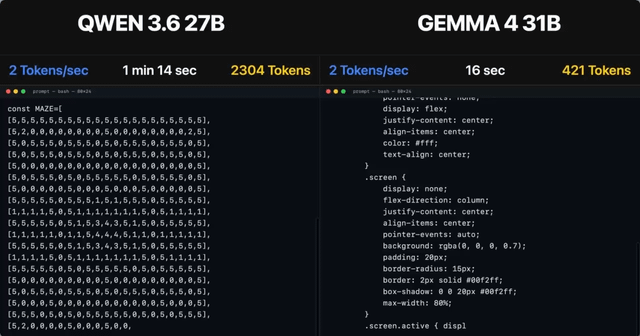
Qwen 3.6 35B A3B, RTX 5090 32GB, 187t/s, Q5 K S, 120K Context Size, Thinking Mode Off, Temp 0.1
The content details the performance of the Qwen 3.6 35B A3B model, achieving 187 tokens per second on an RTX 5090 32GB GPU. It highlights support for a 120K context size, using Q5 K S quantization and a temperature of 0.1.
42