RESEARCHDEV.to AI·4/24/2026
Kimi K2.6 Benchmark: Results vs GPT-5.4, Claude, Gemini, and K2.5
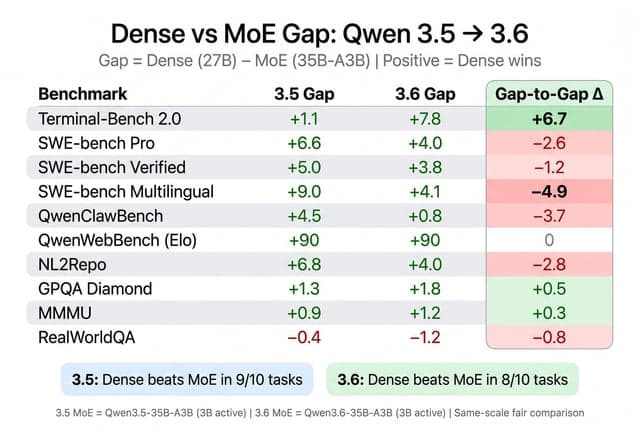
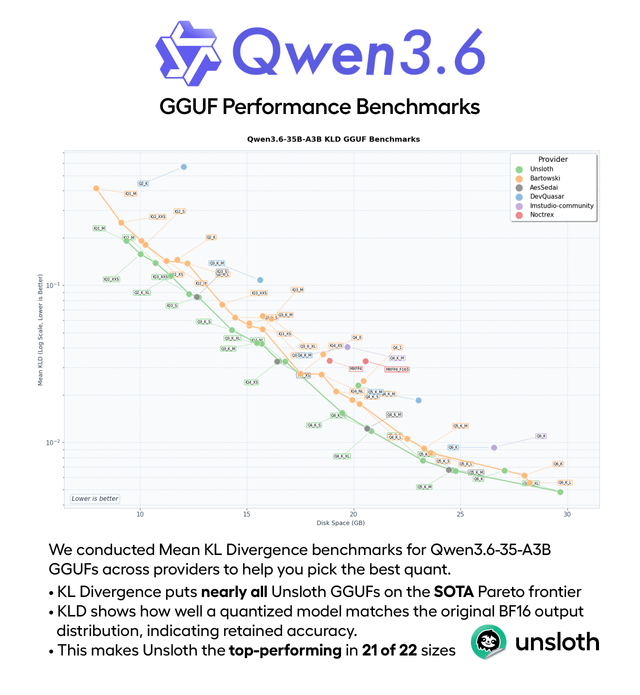
This content analyzes the Kimi K2.6 benchmark results compared to GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, and Kimi K2.5, using a standardized reference table. K2.6 demonstrates strong performance in coding and agentic tasks, clearly ahead of its predecessor and closing the gap with frontier proprietary models.
61