ARTICLE↑ trendingReddit r/LocalLLaMA·4/22/2026
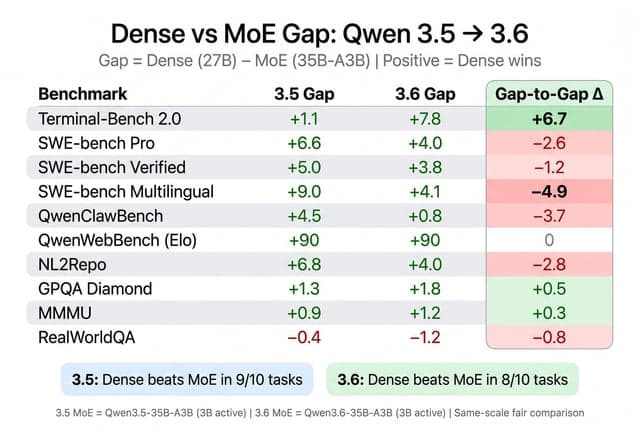
Forgive my ignorance but how is a 27B model better than 397B?
A user expresses confusion regarding how a 27B dense model could outperform a 397B Mixture-of-Experts (MoE) model, specifically mentioning Qwen, and questions the utility of the additional experts.

46