ARTICLE↑ trendingReddit r/LocalLLaMA·4/23/2026
POV Qwen 3.5 with thinking
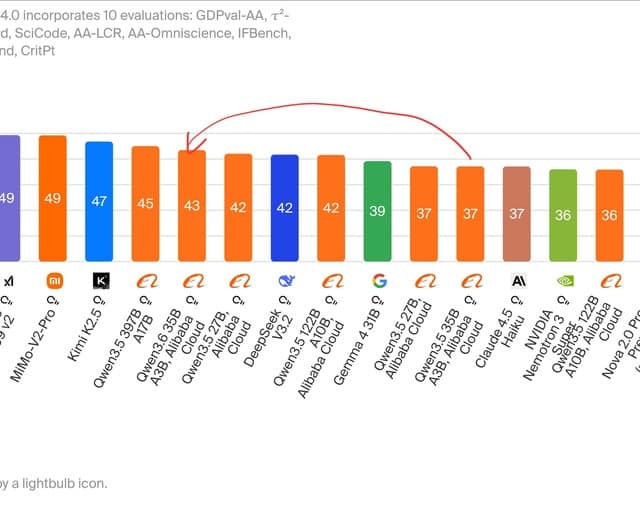
This content discusses the behavior of the AI model Qwen 3.5, which frequently gets stuck in thinking loops. The author makes a brief, informal observation about this characteristic of the model.

47