RESEARCH↑ trendingReddit r/LocalLLaMA·16/4/2026
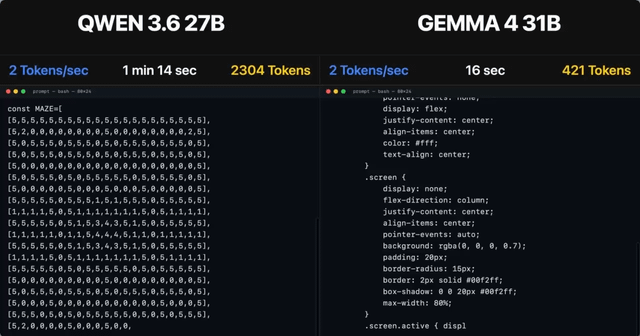
Qwen 3.6 35B A3B, RTX 5090 32GB, 187t/s, Q5 K S, 120K Context Size, Thinking Mode Off, Temp 0.1
El contenido detalla el rendimiento del modelo Qwen 3.6 35B A3B, alcanzando 187 tokens por segundo en una GPU RTX 5090 de 32GB. Destaca el soporte para un tamaño de contexto de 120K, utilizando cuantificación Q5 K S y una temperatura de 0.1.
42