RESEARCHDEV.to AI·24/4/2026
Kimi K2.6 Benchmark: Results vs GPT-5.4, Claude, Gemini, and K2.5
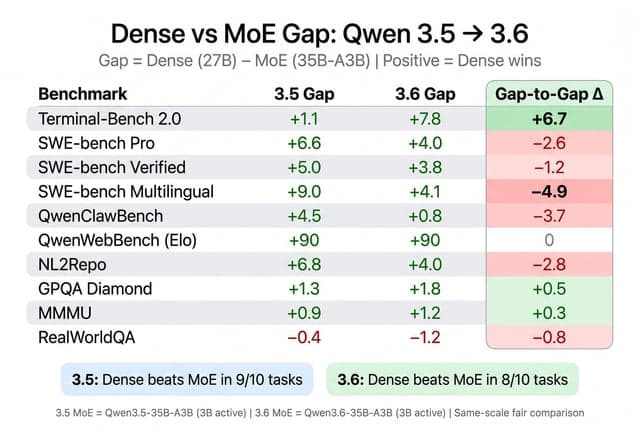
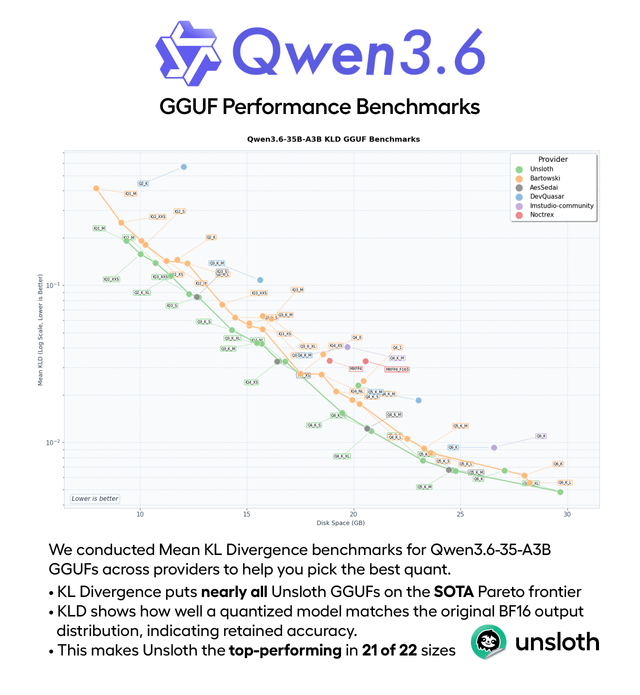
Este contenido analiza los resultados del benchmark Kimi K2.6 en comparación con GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro y Kimi K2.5, utilizando una tabla de referencia estandarizada. K2.6 muestra un rendimiento sólido en codificación y tareas de agente, superando a su predecesor y acercándose a los modelos propietarios de vanguardia.
61