NEWS↑ trendingReddit r/LocalLLaMA·12/4/2026
GLM 5.1 sits alongside frontier models in my social reasoning benchmark
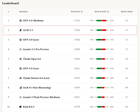
GLM 5.1 demuestra ser muy competitivo en razonamiento social frente a modelos de vanguardia, según un benchmark propio basado en juegos de Blood on the Clocktower. El modelo es notablemente más económico, costando $0.92 por partida en comparación con los $3.69 de Claude Opus 4.6, y tiene una tasa de error de herramienta del 0%.
43