CASE↑ trendingReddit r/LocalLLaMA·23/4/2026
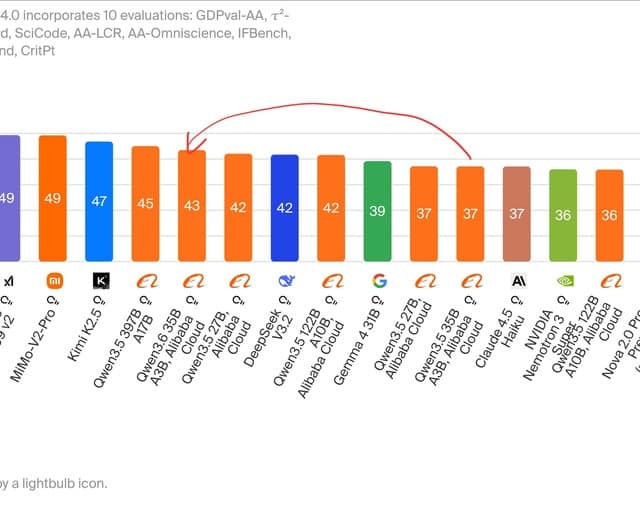
Qwen 3.6 27B is a BEAST
Un usuario informa que Qwen 3.6 27B, ejecutado localmente en una computadora portátil, sobresale en tareas de ciencia de datos como llamadas a herramientas y depuración de transformación de datos. Su rendimiento fue tan impresionante que están considerando cancelar las suscripciones a la nube, encontrándolo perfecto para trabajos con pyspark/python.
56