ARTICLE↑ trendingReddit r/LocalLLaMA·22/4/2026
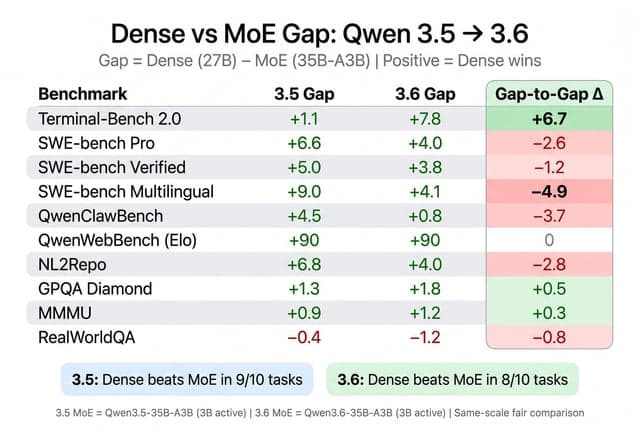
Forgive my ignorance but how is a 27B model better than 397B?
Un usuario expresa confusión sobre cómo un modelo denso de 27B puede ser superior a un modelo MoE de 397B, mencionando Qwen, y cuestiona la utilidad de los expertos adicionales.

46