NEWS↑ trending43
GLM 5.1 sits alongside frontier models in my social reasoning benchmark
Reddit r/LocalLLaMA·12 avril 2026
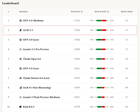
GLM 5.1 se montre très compétitif en raisonnement social face aux modèles de pointe, selon un benchmark personnalisé basé sur des jeux autonomes de Blood on the Clocktower. Il offre une efficacité de coût significative à 0,92 $ par partie, contre 3,69 $ pour Claude Opus 4.6, avec un taux d'erreur d'outil de 0 %.
Lire l'original ↗