ARTICLE↑ trending43
Qwen-3.6-27B, llamacpp, speculative decoding - appreciation post
Reddit r/LocalLLaMA·23 avril 2026
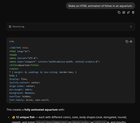
Le contenu décrit une expérience démontrant des gains de vitesse significatifs (jusqu'à 68.35 tokens/s) en utilisant le décodage spéculatif avec le modèle Qwen-3.6-27B via llamacpp. L'auteur met en évidence la capacité de l'IA à générer et déboguer du code efficacement.
Lire l'original ↗