RESEARCH↑ trendingReddit r/LocalLLaMA·16/04/2026
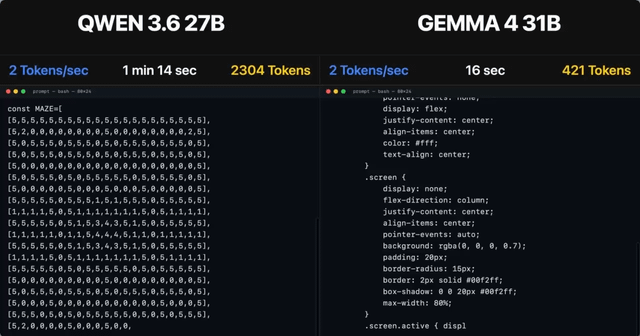
Qwen 3.6 35B A3B, RTX 5090 32GB, 187t/s, Q5 K S, 120K Context Size, Thinking Mode Off, Temp 0.1
Le contenu détaille les performances du modèle Qwen 3.6 35B A3B, atteignant 187 tokens par seconde sur un GPU RTX 5090 32GB. Il met en évidence la prise en charge d'une taille de contexte de 120K, utilisant une quantification Q5 K S et une température de 0.1.
42