ARTICLE↑ trendingReddit r/LocalLLaMA·23/04/2026
Qwen3.6 can code
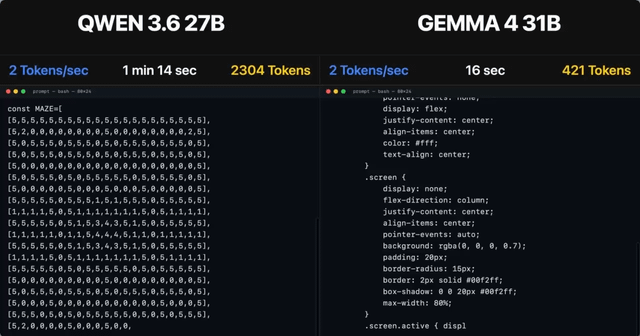
Un utilisateur, frustré par les modèles OpenAI, a essayé Qwen3.6-27b pour générer du code Svelte 5 et a obtenu un résultat parfait, bien que cela ait pris plus de temps. Il anticipe des développements intéressants au cours des 12 prochains mois, malgré le caractère informel de l'évaluation.
52
![Qwen3 4B outperforms cloud agents on code tasks—with Mahoraga research [R]](/cdn-cgi/image/width=3840,quality=75,format=webp/https://external-preview.redd.it/vJR39F6E0ARypSJNijuQ-yR1Ycl5eGsa5LcRuS3CoSM.png?width=140&height=70&auto=webp&s=6b39ed3b63f9683d366c205696aa8805c9cf6143)