ARTICLE↑ trendingReddit r/LocalLLaMA·22/04/2026
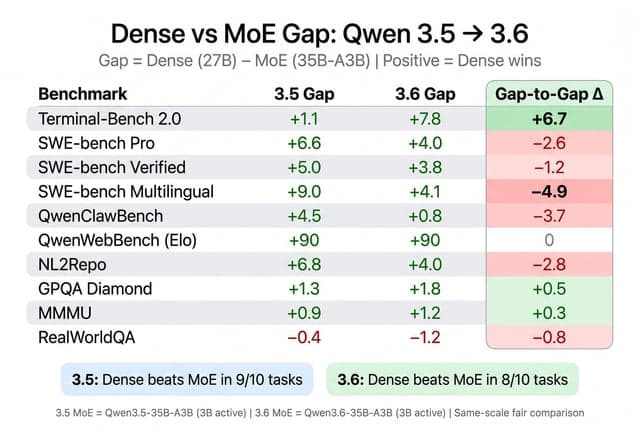
Forgive my ignorance but how is a 27B model better than 397B?
Un utilisateur exprime sa confusion sur la manière dont un modèle dense de 27 milliards de paramètres pourrait être meilleur qu'un modèle MoE de 397 milliards, en particulier concernant Qwen, et s'interroge sur l'utilité des experts supplémentaires.

46