ARTICLE↑ trendingReddit r/LocalLLaMA·22/04/2026
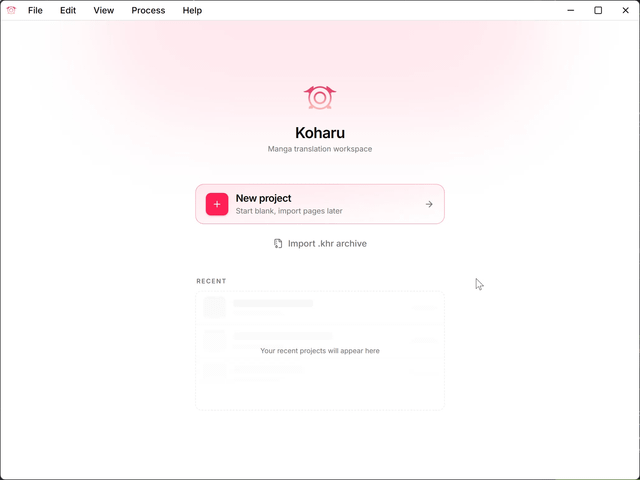
Local manga translator with LLM build-in, written in Rust with llama.cpp integration
Ce projet est un traducteur de mangas et d'images, écrit en Rust, qui utilise la détection d'objets, l'OCR visuel basé sur les LLM, l'analyse de mise en page et des modèles d'inpainting. Il intègre llama.cpp pour le support des LLM locaux comme Gemma et Qwen, offrant un pipeline performant et facile à utiliser.
43
![NuExtract3 released: open-weight 4B VLM for Markdown, OCR and structured extraction (self-hostable) [P]](/cdn-cgi/image/width=3840,quality=75,format=webp/https://preview.redd.it/pm2xbooyxn2h1.png?width=140&height=78&auto=webp&s=30ec102187e4eb4582c79f124c41b8a3c129d1fd)