ARTICLE↑ trending42
LM Studio CPU thread pool size vs. tk/s with some MoE layers offloaded to CPU
Reddit r/LocalLLaMA·18. April 2026
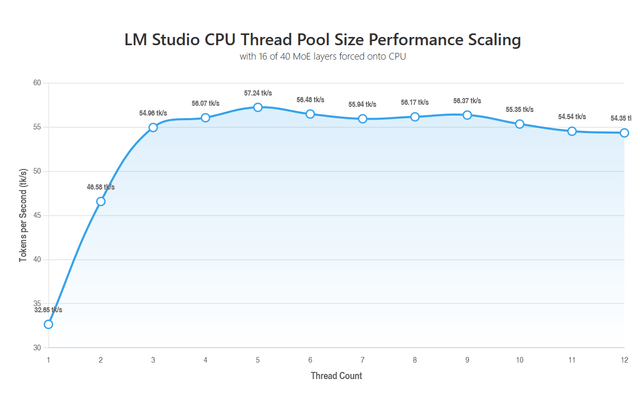
Dieser Inhalt analysiert die Beziehung zwischen der CPU-Thread-Pool-Größe in LM Studio und der Token-Generierungsgeschwindigkeit (tk/s). Er konzentriert sich dabei speziell auf Szenarien, in denen einige Mixture of Experts (MoE)-Schichten auf die CPU ausgelagert werden, um die Leistung zu optimieren.
Original lesen ↗