ARTICLE↑ trendingReddit r/LocalLLaMA·4/22/2026
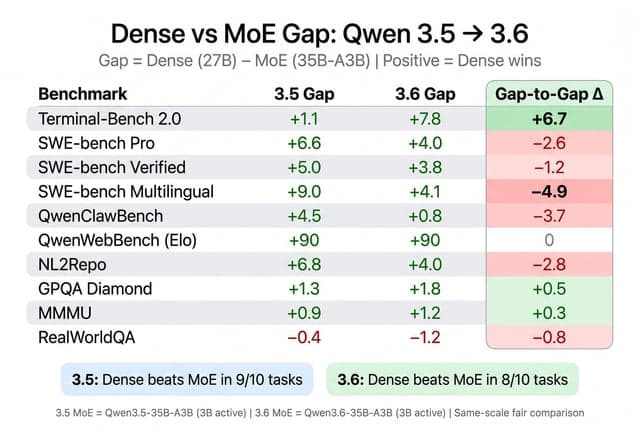
Forgive my ignorance but how is a 27B model better than 397B?
Ein Nutzer drückt seine Verwirrung darüber aus, wie ein 27B dichtes Modell besser sein kann als ein 397B MoE-Modell, insbesondere in Bezug auf Qwen, und hinterfragt den Nutzen der zusätzlichen Experten.

46