ARTICLEDEV.to AI·vor 22T
How to tell whether an AI capability pack can actually help you ship
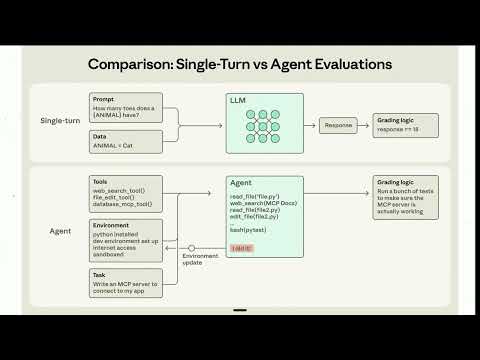
Dieser Artikel erläutert, wie ein wirklich nützliches KI-Fähigkeitspaket identifiziert werden kann, und unterscheidet es von einer bloßen Prompt-Sammlung. Er betont, dass der wahre Wert darin liegt, einem KI-Agenten zu helfen, evidenzbasiert zu arbeiten, Ergebnisse zu überprüfen und Fehler effektiv zu melden.
28