ARTICLE↑ trending42
MiniMax-M2.7 vs Qwen3.5-122B-A10B for 96GB VRAM full offload?!
Reddit r/LocalLLaMA·April 12, 2026
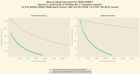
The author compares MiniMax-M2.7 and Qwen3.5-122B-A10B GGUF models for local full offload on a 96GB VRAM rig. For their purposes, Qwen3.5-122B is preferred, despite MiniMax being more quantized, highlighting the trade-offs in performance for local LLM inference.
Read original ↗