RESEARCHarXiv CS.LG·6d ago
Self-Distilled Policy Gradient
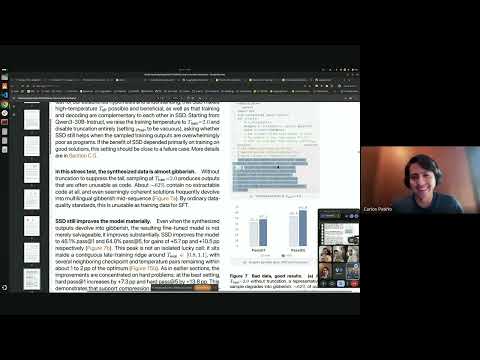
This paper introduces Self-Distilled Policy Gradient (SDPG), a novel framework that enhances sparse-reward reinforcement learning through on-policy self-distillation. SDPG integrates group-relative verifier advantages, exact full-vocabulary self-distillation, and KL regularization, demonstrating improved stability and performance over existing baselines.
28