ARTICLEDEV.to AI·hace 22d
How to tell whether an AI capability pack can actually help you ship
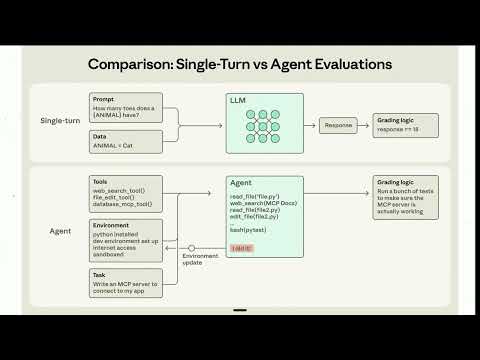
Este artículo explica cómo identificar un paquete de capacidad de IA verdaderamente útil, diferenciándolo de una simple colección de prompts. Destaca que el valor real reside en ayudar a un agente de IA a trabajar con evidencia, verificar resultados e informar fallas de manera efectiva.
28