RESEARCH↑ trendingReddit r/LocalLLaMA·18/4/2026
Qwen3.6-35B-A3B-Uncensored-Wasserstein-GGUF
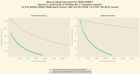
Un usuario descubrió y solucionó un problema significativo de deriva de tensor en las capas `ssm_conv1d` de los modelos Qwen3.6-35B GGUF cuantificados, proponiendo la métrica de Wasserstein como superior a Kullback Leibler para detectar inestabilidad numérica. La solución, que se dirige específicamente a las capas de transición de estado recurrente responsables de la memoria de contexto largo, ya está disponible en un modelo compartido.
44