RESEARCH↑ trendingReddit r/LocalLLaMA·06/05/2026
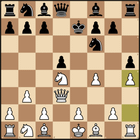
Quality comparison between Qwen 3.6 27B quantizations (BF16, Q8_0, Q6_K, Q5_K_XL, Q4_K_XL, IQ4_XS, IQ3_XXS,...)
Ce contenu compare la qualité de différentes quantifications du modèle Qwen 3.6 27B à l'aide d'un test de jeu d'échecs personnalisé afin de trouver l'option optimale pour les configurations avec 16 Go de VRAM. Il évalue la capacité des modèles à suivre les états du plateau et à générer des images SVG précises.
42