RESEARCH↑ trendingReddit r/MachineLearning·14/04/2026
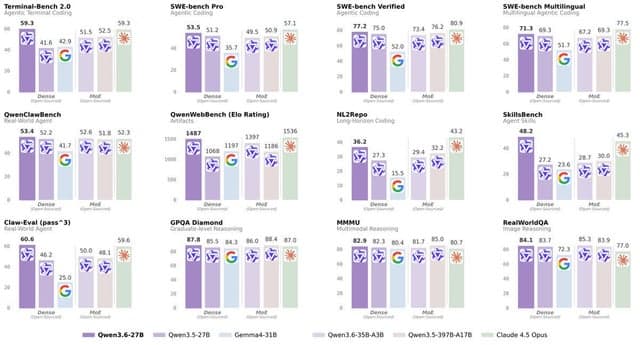
We benchmarked TranslateGemma against 5 other LLMs on subtitle translation across 6 languages. At first glance the numbers told a clean story, but then human QA added a chapter. [D]
Este conteúdo apresenta um estudo de benchmark que avaliou seis Modelos de Linguagem Grandes (LLMs), incluindo TranslateGemma-12b, na tradução de legendas de inglês para seis idiomas. Os modelos foram classificados usando métricas de Avaliação de Qualidade (QE) sem referência e uma métrica combinada personalizada chamada TQI, onde TranslateGemma-12b emergiu como o modelo com melhor desempenho geral.
![We benchmarked TranslateGemma against 5 other LLMs on subtitle translation across 6 languages. At first glance the numbers told a clean story, but then human QA added a chapter. [D]](/cdn-cgi/image/width=3840,quality=75,format=webp/https://preview.redd.it/h6gfrd0ew4vg1.jpg?width=140&height=140&crop=1:1,smart&auto=webp&s=d586892e18bb809fa52e1595acdd73dd93bcdd8a)
70