RESEARCH↑ trendingReddit r/MachineLearning·vor 27T
Learning, Fast and Slow: Towards LLMs That Adapt Continually [R]
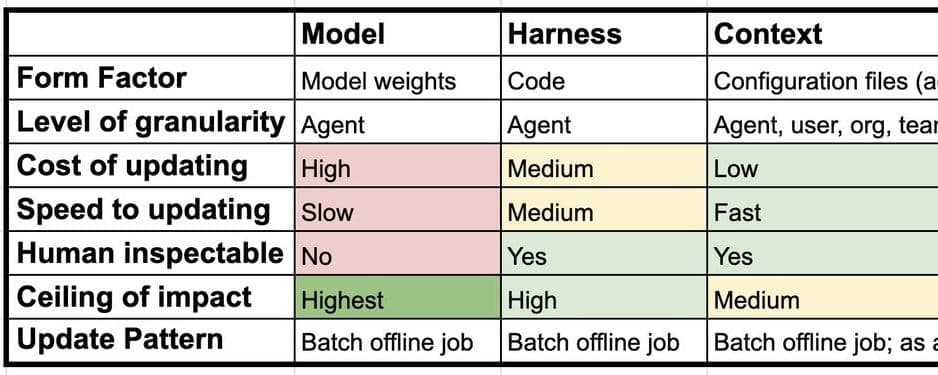
Große Sprachmodelle (LLMs) sind mit katastrophalem Vergessen und Plastizitätsverlust konfrontiert, wenn sie ihre Parameter für nachgelagerte Aufgaben aktualisieren. Diese Arbeit stellt ein "schnell-langsam"-Lernframework für LLMs vor, das Modellparameter als langsame Gewichte und optimierten Kontext als schnelle Gewichte nutzt, um sich effizient anzupassen, ohne das allgemeine Denkvermögen zu beeinträchtigen.
42