RESEARCH↑ trendingReddit r/LocalLLaMA·4/18/2026
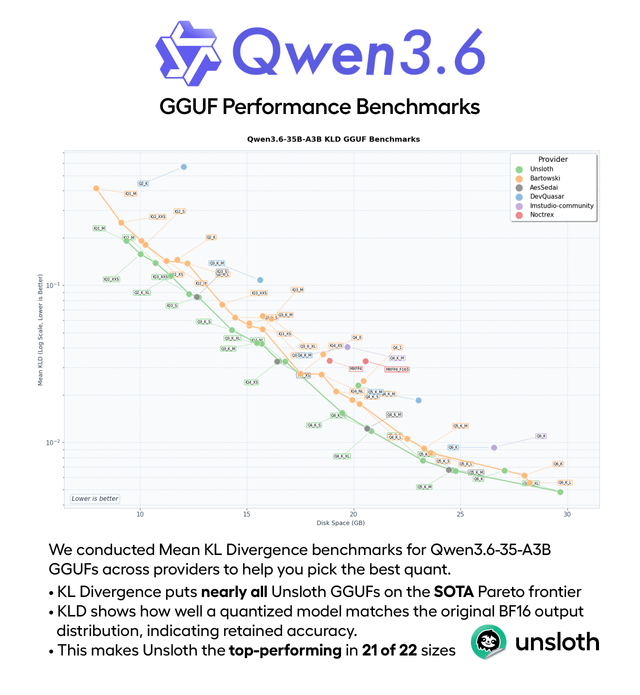
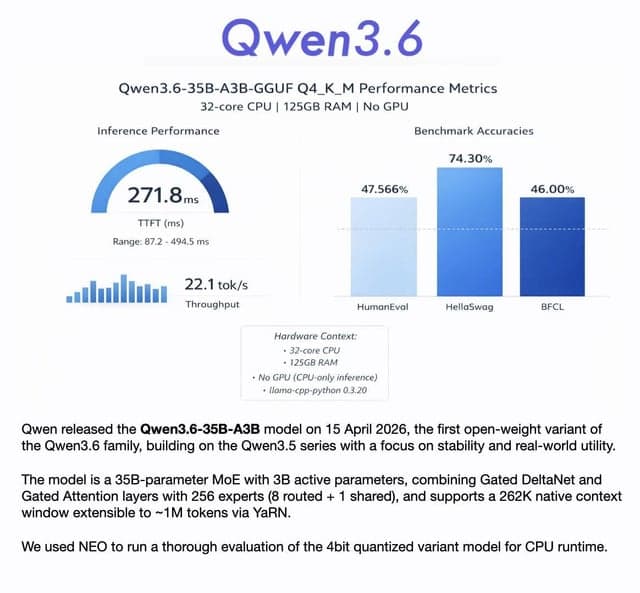
Qwen 3.6 35B A3B Q4_K_M quant evaluation
Dieser Inhalt bewertet die Leistung des quantisierten MoE-Modells Qwen 3.6 35B A3B Q4_K_M auf der CPU, unter Verwendung von Benchmarks wie HumanEval, HellaSwag und BFCL. Es erreichte 22 Tokens/Sekunde und zeigte eine starke Leistung bei Schlussfolgerungen des gesunden Menschenverstandes (74%) sowie solide Ergebnisse für ein aktives 3B MoE-Modell.
42