ARTICLEDEV.to AI·4/18/2026
Opus 4.7 Uses 35% More Tokens Than 4.6. Here's What I'm Doing About It.
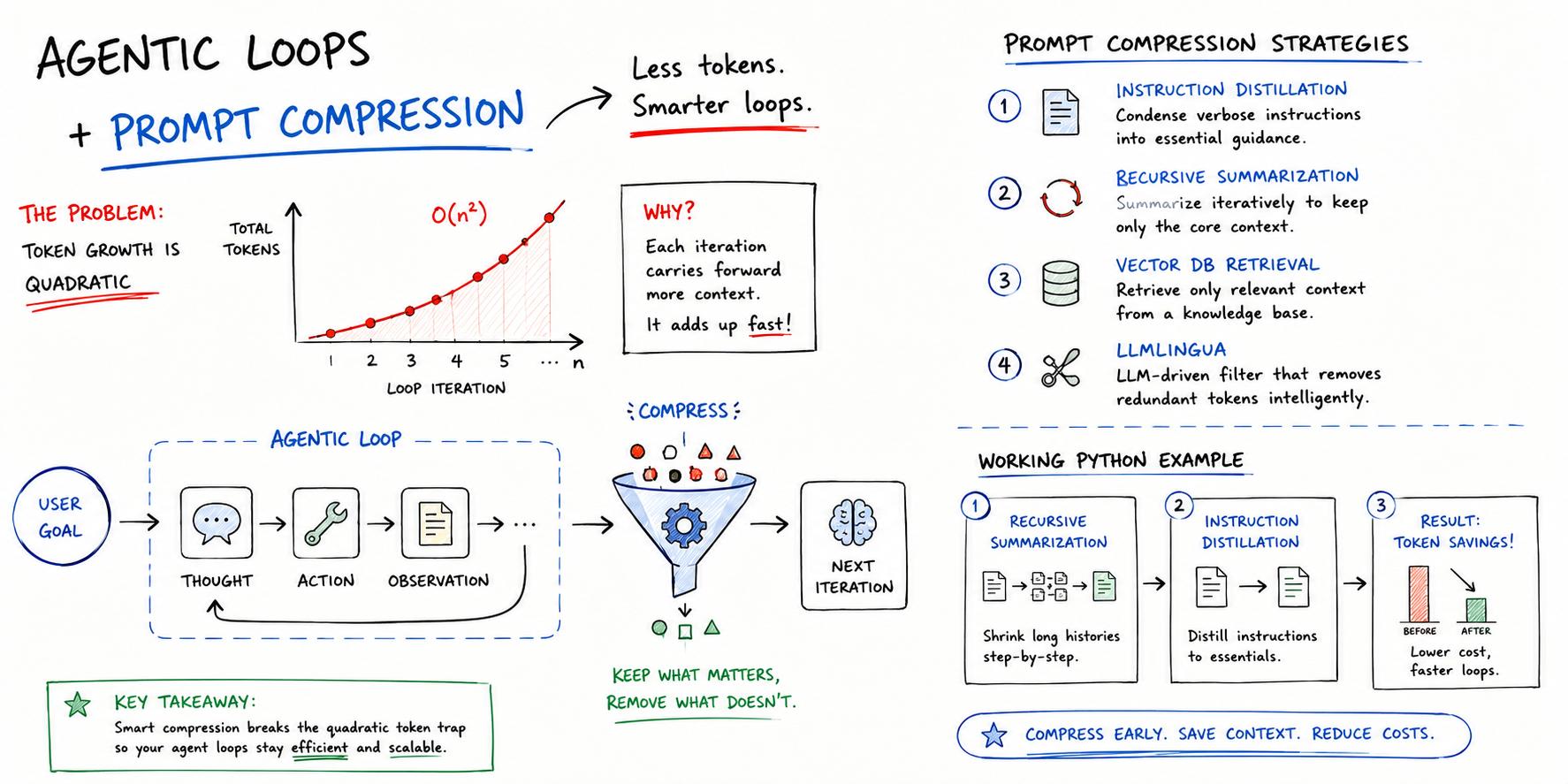
Claude Opus 4.7's new tokenizer is causing an effective 35% price increase for the same work due to higher token consumption compared to version 4.6. While reasoning improvements are real for complex tasks, the author plans to use 4.7 selectively and stick with 4.6 for tasks where token efficiency is key.
27