ARTICLE↑ trendingReddit r/LocalLLaMA·4/13/2026
Experiment: Olmo 3 7B Instruct Q1_0
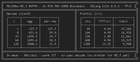
The author attempted to quantize OLMo-3 7B Instruct into a 1-bit format using quantization aware distillation, training the model for 12 hours on 4x B200 GPUs. Although the resulting model can produce basic English, it's generally unusable due to repetition loops and lack of context tracking, attributed to premature training cessation and an unsuitable dataset choice.

43