RESEARCH↑ trendingReddit r/LocalLLaMA·4/17/2026
Qwen3.6 GGUF Benchmarks
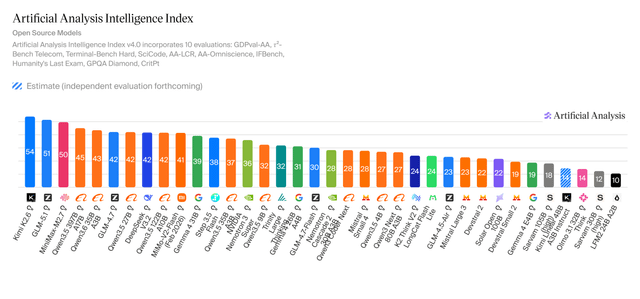
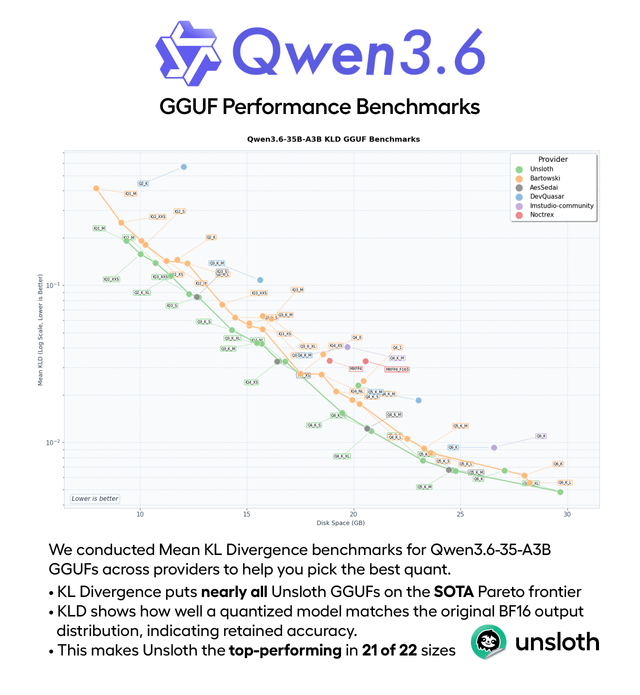
This content presents KLD performance benchmarks for Unsloth's Qwen3.6-35B-A3B GGUF quants, highlighting their efficiency in terms of KLD versus disk space. It also clarifies that frequent GGUF updates are typically due to external bug fixes or official improvements, rather than Unsloth's internal errors.
41