ARTICLE↑ trendingReddit r/LocalLLaMA·18/4/2026
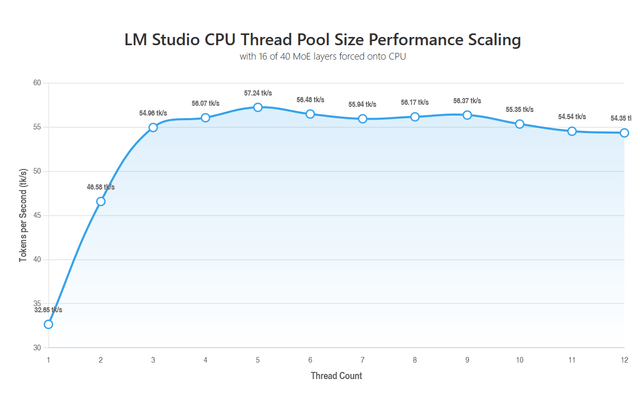
LM Studio CPU thread pool size vs. tk/s with some MoE layers offloaded to CPU
Este contenido analiza la relación entre el tamaño del grupo de hilos de la CPU en LM Studio y la velocidad de generación de tokens (tk/s). Se enfoca específicamente en escenarios donde algunas capas del modelo Mixture of Experts (MoE) son descargadas a la CPU para optimizar el rendimiento.
42