ARTICLEDEV.to AI·il y a 22j
How to tell whether an AI capability pack can actually help you ship
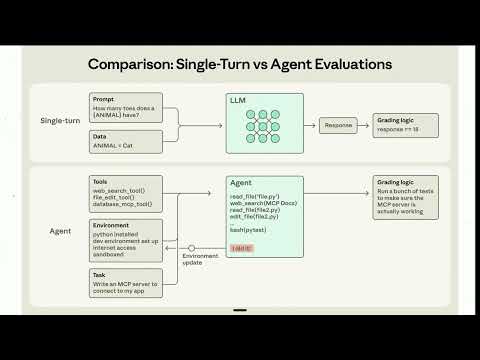
Cet article explique comment identifier un pack de capacités d'IA véritablement utile, le distinguant d'une simple collection de prompts. Il souligne que la vraie valeur réside dans l'aide apportée à un agent d'IA pour travailler à partir de preuves, vérifier les résultats et signaler les échecs.
28