RESEARCH↑ trendingReddit r/LocalLLaMA·18/04/2026
Qwen3.6-35B-A3B-Uncensored-Wasserstein-GGUF
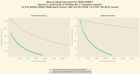
Un utilisateur a découvert et corrigé un problème significatif de dérive de tenseur dans les couches `ssm_conv1d` des modèles Qwen3.6-35B GGUF quantifiés, proposant la métrique de Wasserstein comme supérieure à Kullback Leibler pour détecter l'instabilité numérique. La correction, qui cible spécifiquement les couches de transition d'état récurrentes responsables de la mémoire à long contexte, est maintenant disponible dans un modèle partagé.
44