NEWS↑ trendingReddit r/LocalLLaMA·18/04/2026
Cloudflare open-sources lossless LLM compression tool
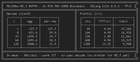
Cloudflare a lancé Unweight, un système de compression sans perte qui réduit la taille des LLM de 15 à 22 % sans sacrifier la précision de sortie. L'outil, qui économise environ 3 Go de VRAM sur les GPU Nvidia H100 pour Llama-3.1-8B, a été mis en open-source sur GitHub avec des plans pour étendre la compression.
44



![torch-nvenc-compress: GPU NVENC silicon as a PCIe bandwidth multiplier — PCA + pure-ctypes Video Codec SDK wrapper. Parallel-path overlap measured at 67% of theoretical max on a real GEMM + encode workload. [P]](/cdn-cgi/image/width=3840,quality=75,format=webp/https://external-preview.redd.it/vqLrMLU0urgSqpiud1c7Ilq7WSsJhRPX63HDDrDRN6M.png?width=640&crop=smart&auto=webp&s=0d43a15121928a0c4b5e3a9730e67ff06df77324)
