CASE↑ trendingReddit r/LocalLLaMA·23/04/2026
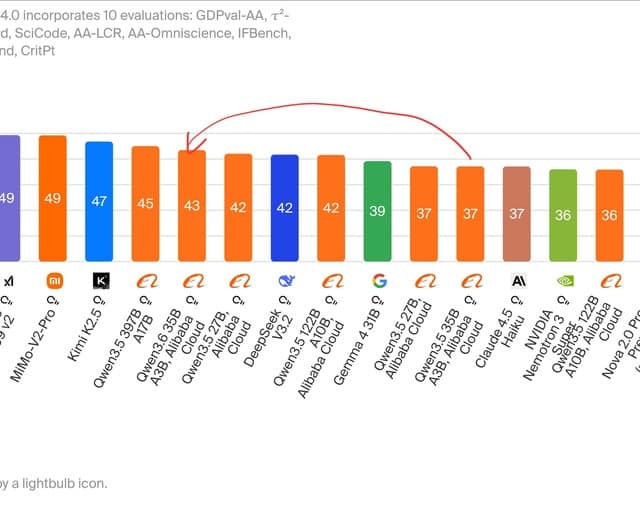
Qwen 3.6 27B is a BEAST
Un utilisateur rapporte que Qwen 3.6 27B, exécuté localement sur un ordinateur portable, excelle dans les tâches de science des données telles que les appels d'outils et le débogage de transformation de données. Ses performances sont si impressionnantes qu'il envisage d'annuler ses abonnements au cloud, le trouvant parfait pour le travail pyspark/python.
56