ARTICLEDEV.to AI·21d ago
How to tell whether an AI capability pack can actually help you ship
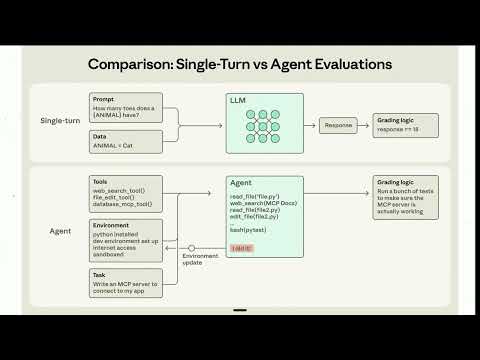
This article explains how to identify a truly useful AI capability pack, distinguishing it from a mere prompt collection. It emphasizes that real value lies in helping an AI agent work from evidence, verify results, and report failures effectively.
28