ARTICLEDEV.to AI·5/9/2026
Beyond Prompt Engineering: The Shift to Agentic Orchestration
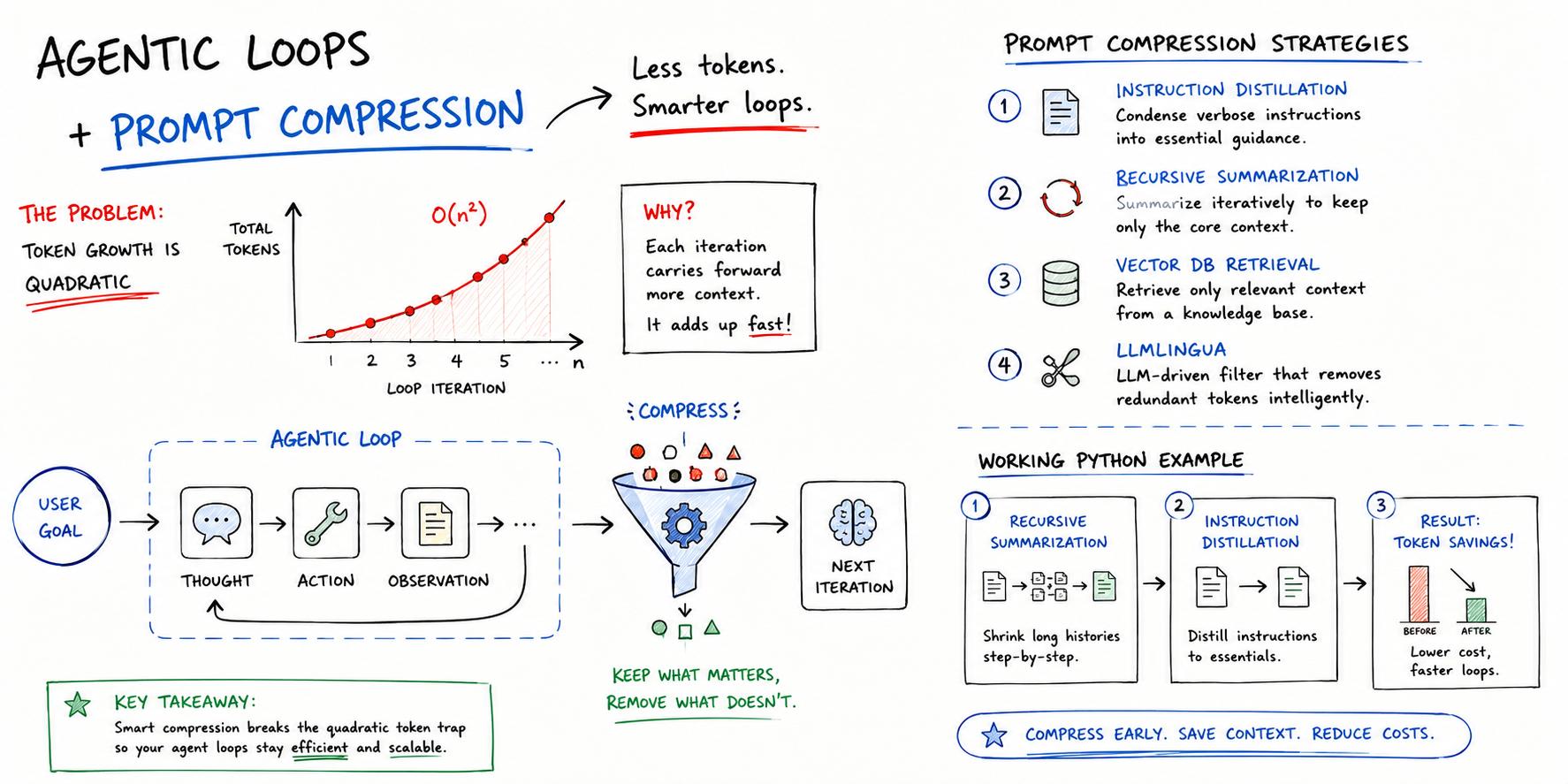
The article describes a shift from prompt engineering, which is brittle and complex for large applications, to agentic orchestration. This new paradigm involves LLMs acting as reasoning engines that control a loop of tools and states, facilitated by frameworks like LangGraph or CrewAI.
27