RESEARCH↑ trendingReddit r/LocalLLaMA·4/18/2026
Qwen 3.6 35B A3B Q4_K_M quant evaluation
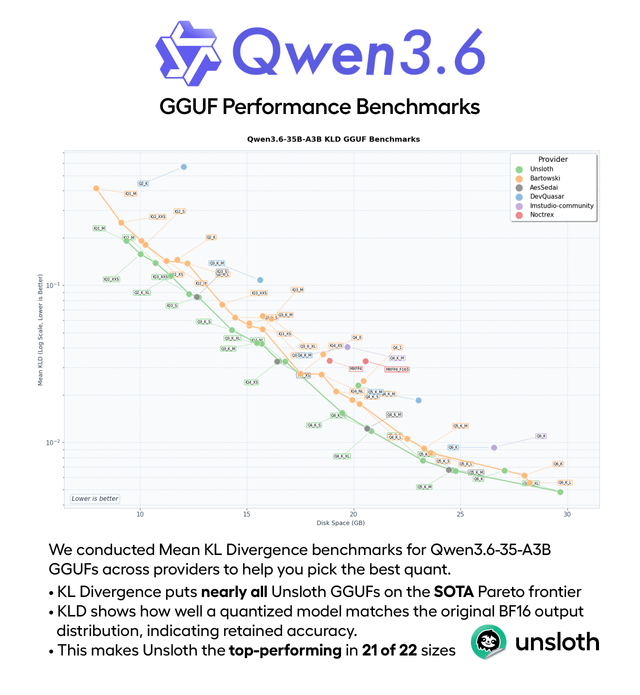
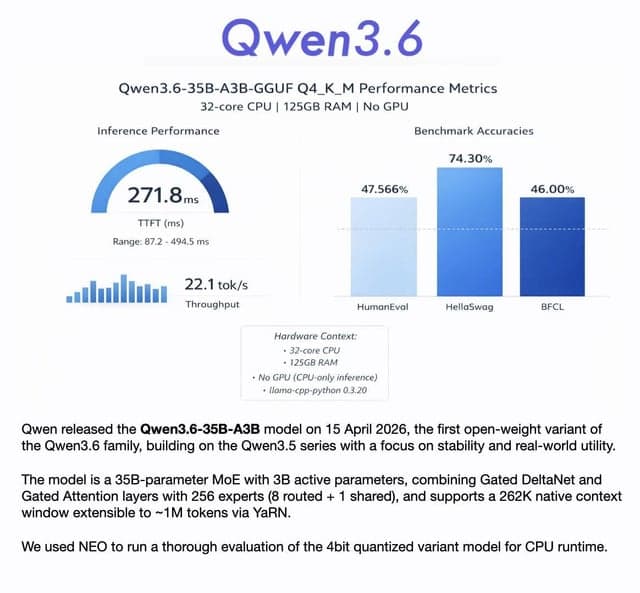
This content evaluates the performance of the Qwen 3.6 35B A3B Q4_K_M quantized MoE model on CPU, using benchmarks like HumanEval, HellaSwag, and BFCL. It achieved 22 tokens/sec, showing strong performance in commonsense reasoning (74%) and solid results for an active 3B MoE model.
42