RESEARCH↑ trendingReddit r/LocalLLaMA·18/4/2026
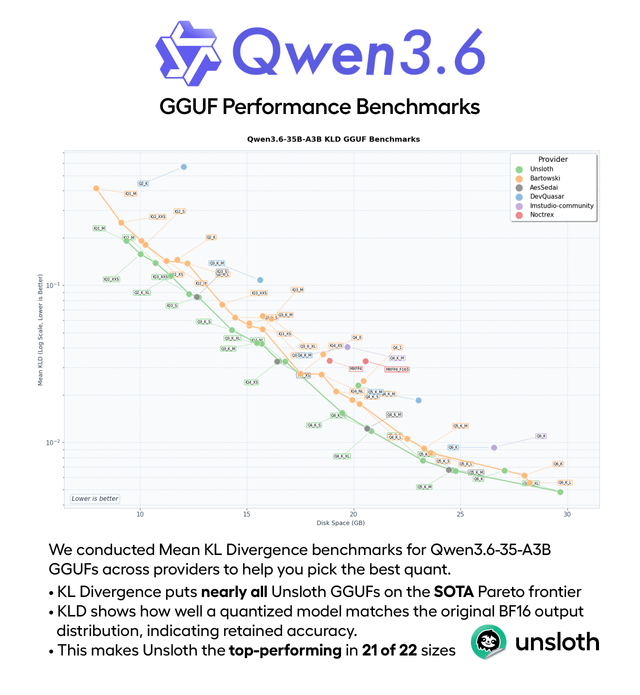
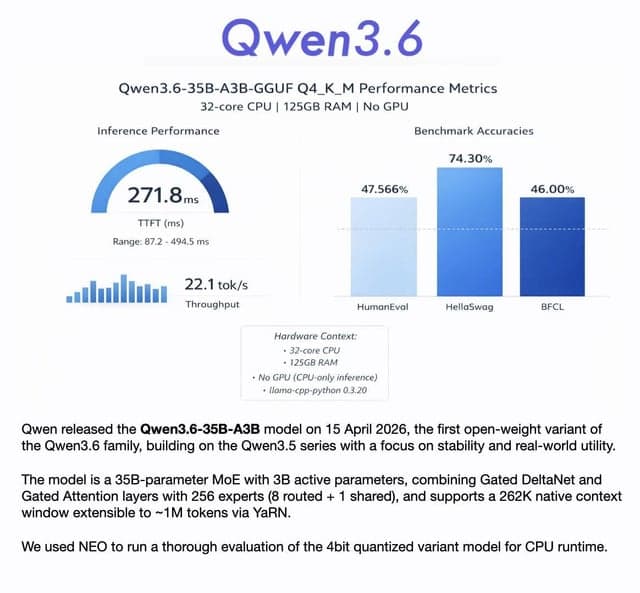
Qwen 3.6 35B A3B Q4_K_M quant evaluation
Este contenido evalúa el rendimiento del modelo MoE cuantificado Qwen 3.6 35B A3B Q4_K_M en CPU, utilizando benchmarks como HumanEval, HellaSwag y BFCL. Alcanzó 22 tokens/seg, mostrando un fuerte rendimiento en razonamiento de sentido común (74%) y resultados sólidos para un modelo MoE activo de 3B.
42