RESEARCHarXiv CS.LG·il y a 14j
ARBITER: Reasoning Trajectory Basins and Majority Vote Failures in Test-Time Sampling
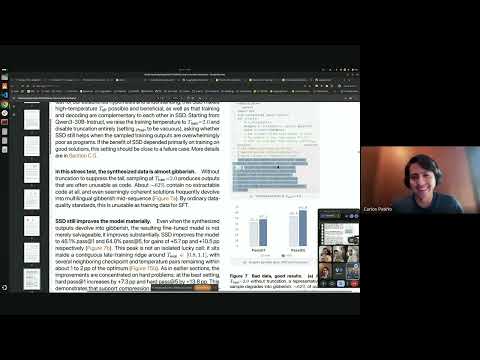
Lorsque les modèles de langage utilisent l'échantillonnage en temps de test et le vote majoritaire, les trajectoires de raisonnement se concentrent en
27