RESEARCH↑ trendingReddit r/LocalLLaMA·18/04/2026
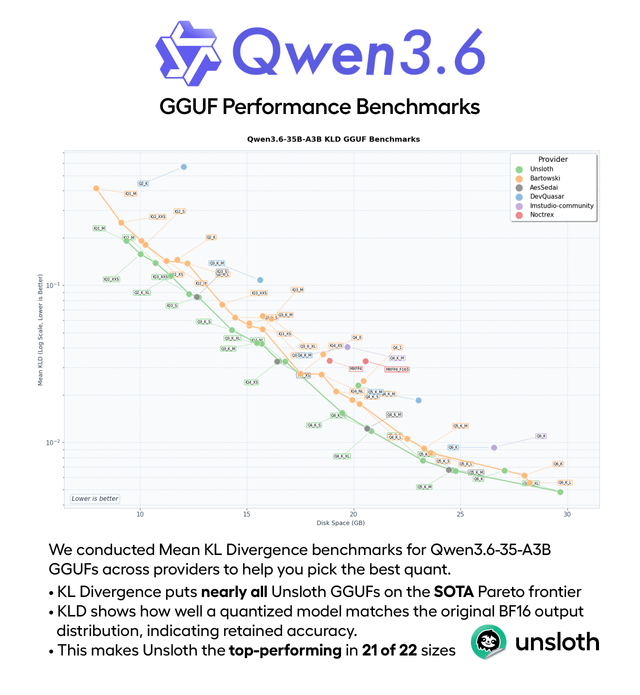
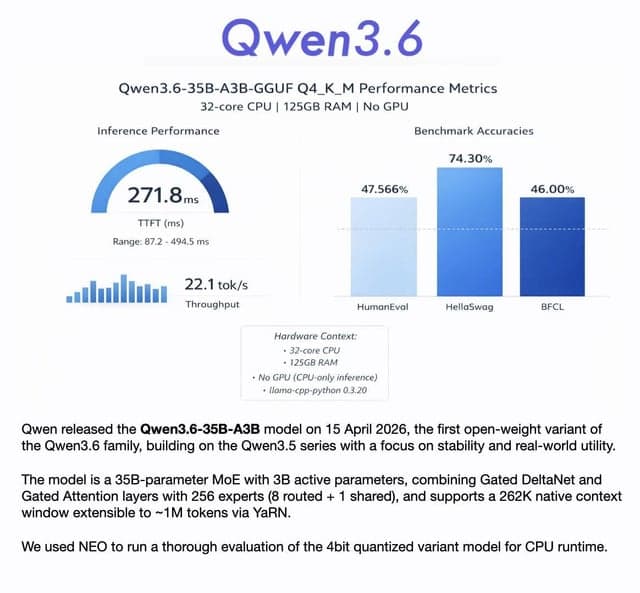
Qwen 3.6 35B A3B Q4_K_M quant evaluation
Ce contenu évalue les performances du modèle MoE quantifié Qwen 3.6 35B A3B Q4_K_M sur CPU, en utilisant des benchmarks comme HumanEval, HellaSwag et BFCL. Il a atteint 22 jetons/sec, montrant de solides performances en raisonnement de bon sens (74%) et des résultats solides pour un modèle MoE actif de 3B.
42