RESEARCH↑ trendingReddit r/MachineLearning·hace 27d
Learning, Fast and Slow: Towards LLMs That Adapt Continually [R]
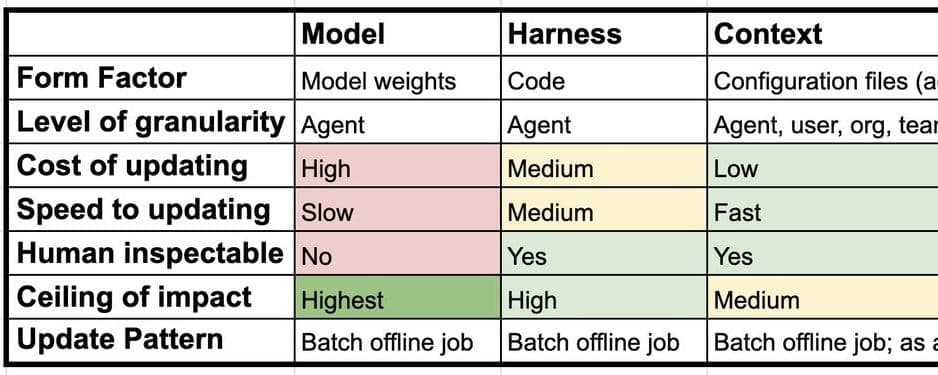
Los grandes modelos de lenguaje (LLM) enfrentan el olvido catastrófico y la pérdida de plasticidad al actualizar sus parámetros para tareas específicas. Este trabajo introduce un marco de aprendizaje "rápido-lento" para LLM, utilizando los parámetros del modelo como pesos lentos y el contexto optimizado como pesos rápidos para adaptarse eficientemente sin comprometer el razonamiento general.
42