ARTICLETogether AI Blog·il y a 8j
Serving MiniMax-M3 for efficient inference: Unlocking 1M-Token Context and Multimodality Without Regrets
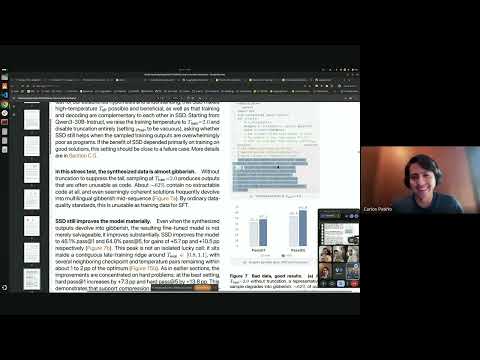
Together a réalisé une inférence efficace pour MiniMax-M3, débloquant un contexte de 1M de tokens et la multimodalité. Ceci a été accompli grâce à l'attention sparse KV-block-major, au décodage MSA paginé, à l'optimisation du score d'index et à une passerelle multimodale basée sur Rust.
27