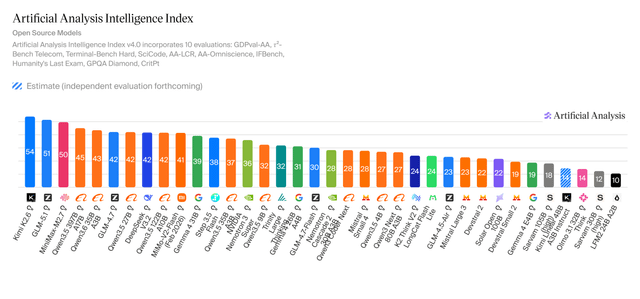
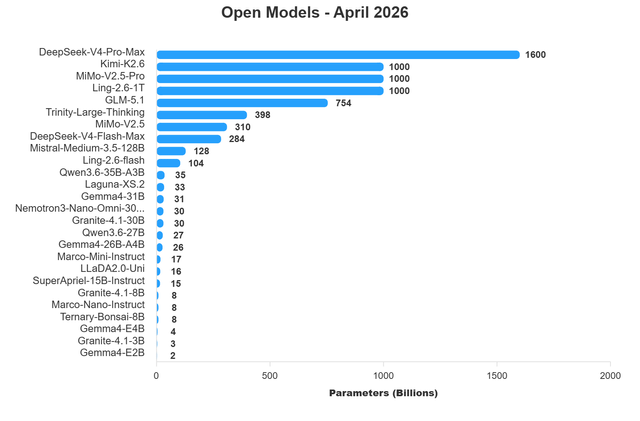
RESEARCH↑ trendingReddit r/LocalLLaMA·17/04/2026
Qwen3.6 GGUF Benchmarks
Ce contenu présente les benchmarks de performance KLD pour les quants GGUF Qwen3.6-35B-A3B d'Unsloth, soulignant leur efficacité par rapport à l'espace disque. Il clarifie également que les mises à jour fréquentes des GGUF sont généralement dues à des corrections de bugs externes ou à des améliorations officielles, et non à des erreurs internes d'Unsloth.
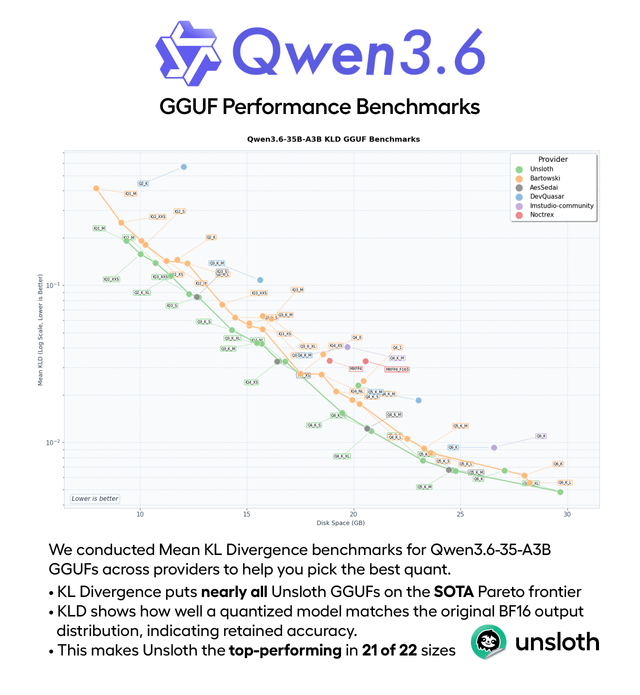
41