ARTICLEDEV.to AI·22/4/2026
Your LLM Isn't the Problem. Your Pipeline Is.
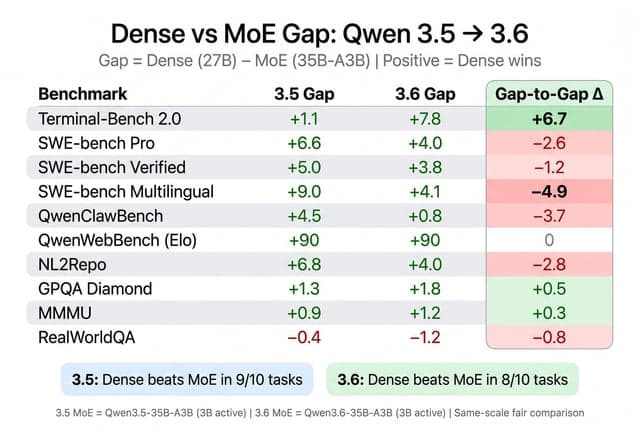
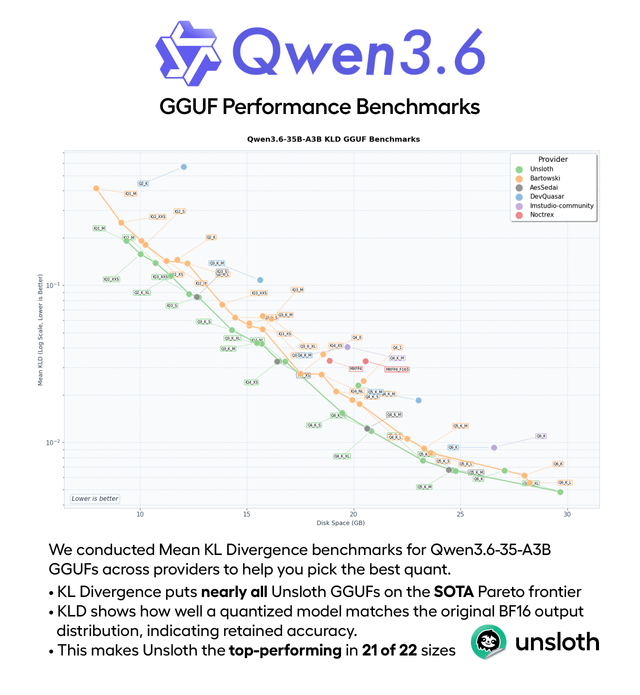
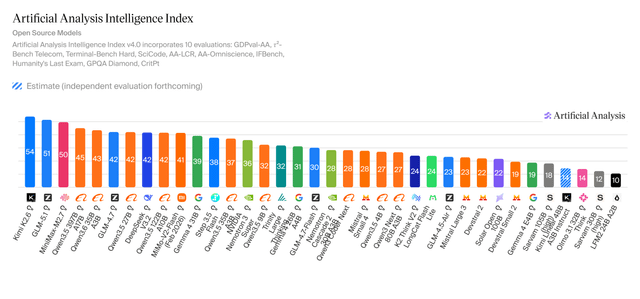
El artículo detalla un problema arquitectónico común en el etiquetado de productos de e-commerce con LLMs, donde las llamadas individuales, aunque correctas, carecen de memoria, lo que fragmenta la taxonomía. El problema no es el LLM, sino que la pipeline no proporciona un vocabulario de etiquetas consistente como entrada.
42