ARTICLE↑ trendingReddit r/LocalLLaMA·30/4/2026
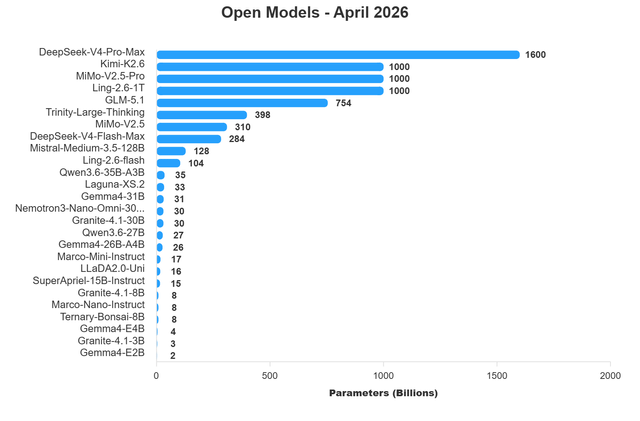
Open Models - April 2026 - One of the best months of all time for Local LLMs?
El contenido analiza modelos abiertos, particularmente LLMs Locales, de abril de 2026, destacándolo como un mes potencialmente excelente para ellos. También señala un cambio de licencia para MiniMax-M2.7 y pide sugerencias de modelos subestimados.
38